Come verificare se un sito è pronto per l’AI: guida al tool Cloudflare isitagentready.com - EVE Milano
Il tool [isitagentready.com](https://isitagentready.com/?utm_source=evemilano.com&utm_medium=referral&utm_campaign=external_links), pubblicato da Cloudflare, esegue un audit automatizzato di una URL contro 18 standard tecnici emergenti che definiscono quanto un sito sia accessibile e utilizzabile da agenti AI: dalla discovery di base (robots.txt, sitemap, Link headers) alla content negotiation in Markdown, dal bot management crittografico (Web Bot Auth) ai protocolli di scoperta MCP, fino ai pattern di pagamento agent-native (x402, MPP, ACP). Lo scanner verifica well-known endpoint, header HTTP e direttive in robots.txt, e restituisce un punteggio progressivo per categoria. Questa guida è un walkthrough completo dei controlli eseguiti dal tool, con la spec di riferimento, il path well-known, un payload minimo di esempio e lo stato di adozione di ogni standard.
isitagentready.com è uno scanner client-side che testa una URL contro un insieme di endpoint `/.well-known/`, header HTTP e direttive in robots.txt rilevanti per l’accesso da parte di agenti AI. Il tool nasce all’interno dell’ecosistema [Cloudflare Agents](https://agents.cloudflare.com/?utm_source=evemilano.com&utm_medium=referral&utm_campaign=external_links) e rappresenta uno dei primi tentativi di consolidare in un’unica rubrica i protocolli che stanno definendo il cosiddetto _agentic web_: un web in cui il client non è più necessariamente un browser umano ma un agente AI che cerca, legge, autentica e — sempre più spesso — paga risorse in autonomia.
Il tool raggruppa i controlli in cinque categorie:
* **Discoverability**: robots.txt, sitemap XML, Link HTTP headers.
* **Content Accessibility**: Markdown content negotiation via `Accept: text/markdown`.
* **Bot Access Control**: regole per user-agent AI in robots.txt, Content Signals, Web Bot Auth.
* **API, Auth, MCP & Skill Discovery**: API Catalog, OAuth/OIDC discovery, OAuth Protected Resource, MCP Server Card, A2A Agent Card, Agent Skills index, WebMCP.
* **Commerce**: x402, MPP, UCP, ACP.
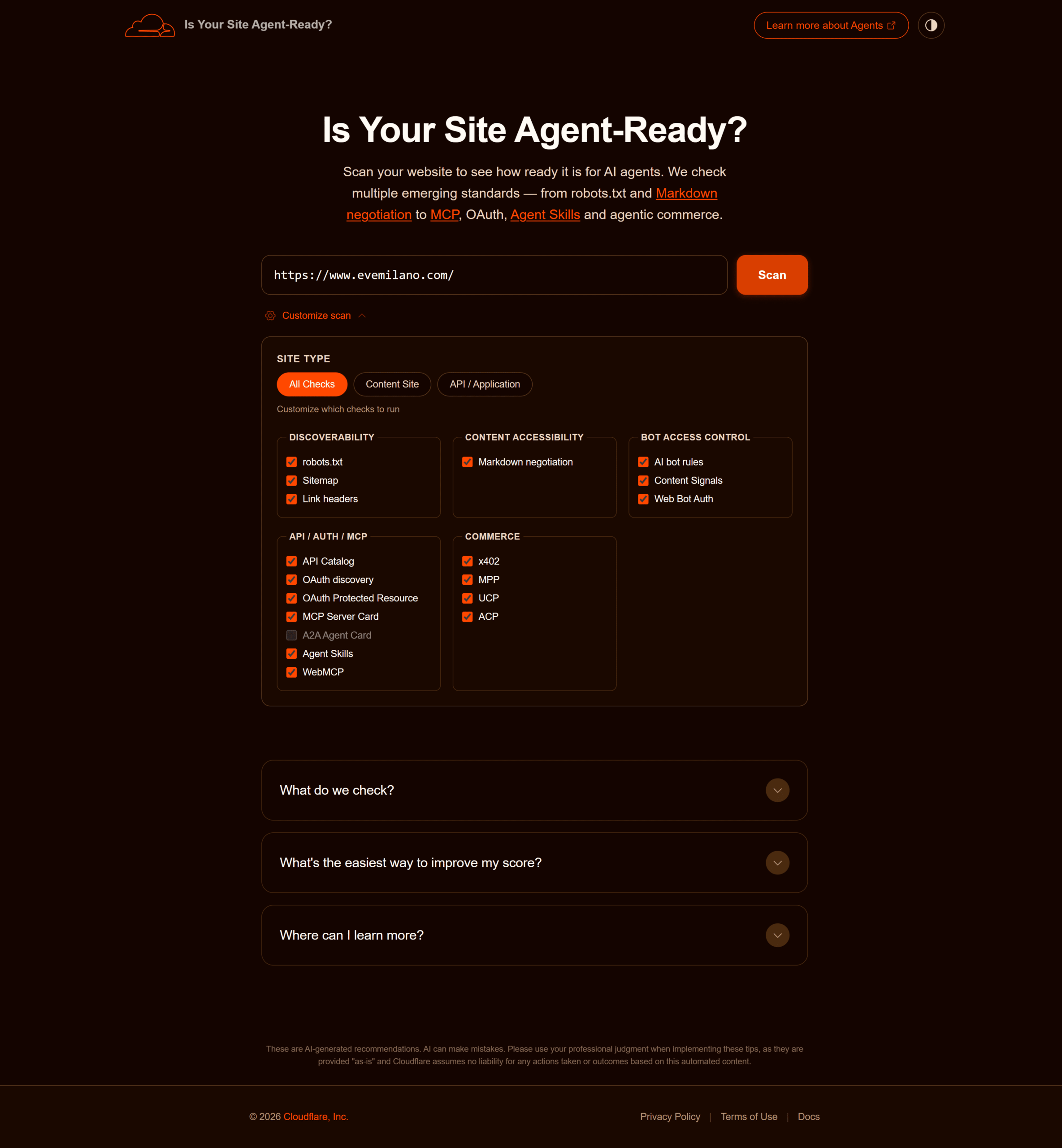
Il pannello _Customize scan_ di isitagentready.com mostra tutti i 18 check raggruppati nelle 5 categorie. Ogni check è disattivabile in base al tipo di sito (content site vs API/application).
Lo scoring è incrementale per categoria. Il primo gradino è **Level 1 — Basic Web Presence**, che corrisponde al rispetto degli standard storici del web (robots.txt, sitemap, Link headers). Il secondo è **Level 2 — Bot-Aware**, raggiunto quando il sito implementa anche il controllo granulare sul traffico AI (regole specifiche per user-agent AI in robots.txt e Content Signals). I gradini successivi richiedono progressivamente l’implementazione degli standard di nuova generazione: content negotiation, signed bot identity, well-known discovery di API e MCP server, fino ai protocolli di pagamento agentico. È importante chiarire che molti dei protocolli verificati sono **draft**, **proprietari** o **in early adoption**: il punteggio non è una metrica SEO classica e non ha un peso noto sul ranking dei motori di ricerca. È una rubrica di _future-readiness_.
Per ancorare la guida a dati concreti, riporto i risultati di due scansioni successive di evemilano.com (WordPress + Cloudflare) eseguite il 12 maggio 2026. La prima, prima di toccare il robots.txt, ha restituito **33/100, Level 1 Basic Web Presence**: il profilo tipico di un blog content-first dietro Cloudflare ma non ancora ottimizzato per i protocolli agentic. La seconda, dopo l’aggiunta delle direttive Content Signals al robots.txt, ha portato il punteggio a **42/100, Level 2 Bot-Aware**, con il check Content Signals che passa da Fail a Pass e la categoria Bot Access Control che chiude a 2/2.
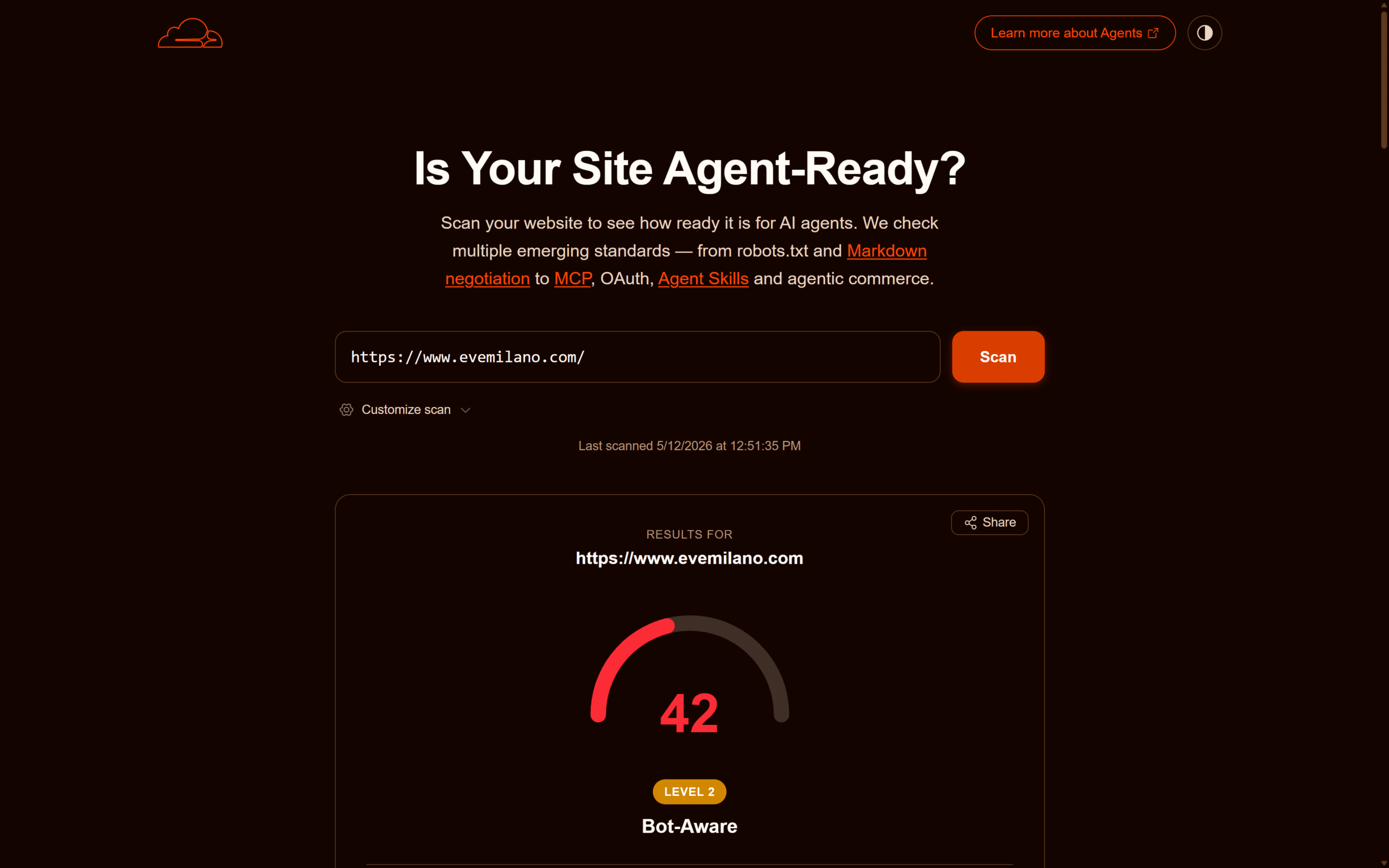
Schermata dei risultati dopo l’aggiunta di Content Signals al robots.txt: punteggio totale 42/100 e classificazione _Level 2 Bot-Aware_.
| Categoria | Prima (Level 1) | Dopo (Level 2) | Check superati (dopo) |
| --- | --- | --- | --- |
| Discoverability | 100 (3/3) | 100 (3/3) | robots.txt, sitemap, Link headers |
| Content Accessibility | 0 (0/1) | 0 (0/1) | no Markdown negotiation |
| Bot Access Control | 50 (1/2) | 100 (2/2) | Content Signals presenti, AI bot rules OK |
| API / Auth / MCP / Skill | 0 (0/6) | 0 (0/6) | nessun well-known agentic |
| Commerce | — | — | opzionale (non e-commerce) |
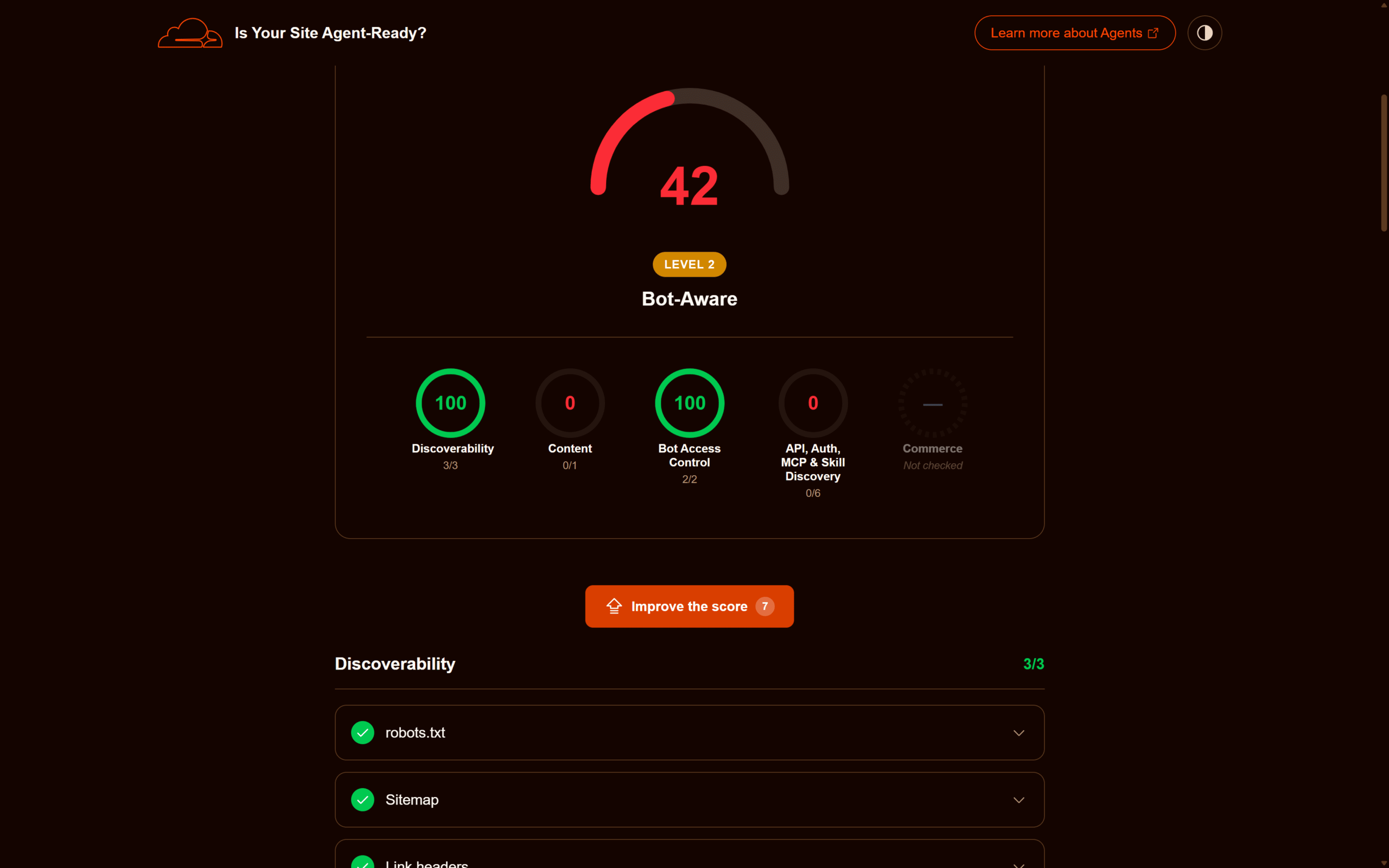
Breakdown per categoria nella vista risultati di isitagentready dopo l’aggiornamento del robots.txt. Bot Access Control passa a 2/2 grazie alle Content Signals.
Il salto da 33 a 42 — e il passaggio da _Level 1_ a _Level 2_ — è arrivato con una modifica chirurgica al robots.txt (poche righe; il dettaglio è nella sezione Content Signals più avanti). L’osservazione operativa è doppia: la prima, che gli interventi a basso costo sui protocolli emergenti spostano davvero il punteggio del tool; la seconda, che la differenza tra Level 2 e i livelli successivi richiede investimenti di altra natura (Markdown negotiation lato edge, well-known agentici, eventualmente MCP server card o Agent Skills index) e raramente è giustificata per un blog content-first.
## Discoverability: i tre pilastri storici del web crawlable
La prima categoria del tool è la più consolidata: i tre standard sono RFC pubblicati o convenzioni de facto con oltre vent’anni di adozione. Per un sito amministrato correttamente, questa categoria dovrebbe essere a 3/3 senza interventi.
### robots.txt — RFC 9309
Il Robots Exclusion Protocol è stato finalmente standardizzato come [RFC 9309](https://datatracker.ietf.org/doc/html/rfc9309?utm_source=evemilano.com&utm_medium=referral&utm_campaign=external_links) nel settembre 2022, dopo decenni di convenzione informale. Il file deve risiedere alla radice del dominio (`/robots.txt`), essere servito con `Content-Type: text/plain` in UTF-8, e contenere almeno una direttiva `User-agent` valida. Le direttive supportate dallo standard sono `user-agent`, `allow`, `disallow` e `sitemap`, con wildcard `*` e end-anchor `$`. La cache è di 24 ore; una risposta 5xx ripetuta equivale a un disallow totale.
Il tool verifica tre cose: status code 200, content-type corretto, presenza di almeno una direttiva `User-agent` valida. Non analizza la logica delle direttive (il sito non viene penalizzato se ha un disallow totale, e nemmeno premiato se distingue tra crawler diversi).
### Sitemap XML
Lo standard sitemap è una convenzione de facto pubblicata su [sitemaps.org](https://www.sitemaps.org/protocol.html?utm_source=evemilano.com&utm_medium=referral&utm_campaign=external_links) (non è un RFC). Il path è libero, ma deve essere dichiarato in robots.txt tramite una direttiva `Sitemap:`. I limiti sono 50.000 URL e 50 MB uncompressed per singolo file; oltre quei limiti serve un _sitemap index_. WordPress genera automaticamente un sitemap index (`/wp-sitemap.xml` in versioni recenti, `/sitemap_index.xml` con Yoast o Rank Math), quindi questo check è in genere superato senza intervento.
Il tool estrae le direttive `Sitemap:` da robots.txt, fa una GET su ogni URL dichiarato e verifica che il payload sia XML valido. Non valida la struttura nel dettaglio (``, ``) né controlla che gli URL elencati siano effettivamente raggiungibili.
L’header HTTP `Link`, definito da [RFC 8288 (Web Linking)](https://datatracker.ietf.org/doc/html/rfc8288?utm_source=evemilano.com&utm_medium=referral&utm_campaign=external_links), permette di dichiarare relazioni tra risorse senza aggiungere markup nel body. La sintassi è `Link: ; rel="relname"; param=value`, con relazioni multiple separate da virgola. Per gli agenti AI, le relazioni più rilevanti sono `alternate` (versione alternativa della risorsa, tipicamente JSON per le pagine WordPress via WP REST API), `describedby`, `service-desc` (descrizione OpenAPI), `api-catalog` (puntatore al catalog dell’API) e `canonical`.
WordPress emette nativamente un header `Link` sulla homepage che include `rel="https://api.w.org/"` (puntatore al REST endpoint) e `rel="alternate"` con `type="application/json"` per ogni post/page renderizzata. Per il tool è sufficiente.
```
Link: .example.com/wp-json/>; rel="https://api.w.org/",
.example.com/wp-json/wp/v2/pages/123>; rel="alternate"; title="JSON"; type="application/json",
.example.com/>; rel="shortlink"
```
## Content Accessibility: Markdown content negotiation
Il check di Content Accessibility verifica un pattern emergente: servire la stessa URL come HTML al browser e come Markdown a un agente AI che richiede esplicitamente `Accept: text/markdown`. Il razionale è semplice: l’HTML di una pagina moderna contiene rumore (script, nav, sidebar, footer, banner cookie) che un LLM deve filtrare a runtime, sprecando token e introducendo errori di estrazione. Servire una versione Markdown già pulita riduce il costo di processing e migliora la qualità dell’estrazione del contenuto principale.
Non esiste un RFC dedicato a questo pattern: si appoggia alla content negotiation standard di [RFC 9110 (HTTP Semantics)](https://datatracker.ietf.org/doc/html/rfc9110?utm_source=evemilano.com&utm_medium=referral&utm_campaign=external_links). Cloudflare promuove l’implementazione lato edge con una feature dedicata che inter
← Retour aux actualités